

今巷でPlanetScaleなる謎のDBが流行っているらしいです。
IT界隈は流行の移り変わりが早いという事で、僕もこのビックウェーブに乗り遅れまいと早速触ってみたので使用感や特徴、導入手順を解説していきます。
これからPlanetScaleの導入を検討している開発者の方の参考になれば嬉しいです。
目次
PlanetScaleとは
PlanetScaleとはPlanetScale Inc.が提供するスケーラブル(拡張性がある)でサーバーレスなMySQLのマネージドサービス。
VitessというMySQLのデータベースソリューションが内部で使われていて、スケーラブルなDBを構築可能です。
既にYouTube, Slack, Github, Shopifyなどの有名テック企業で採用実績があるらしい。
PlanetScale Inc.は2021年6月には3000万ドル(約33億円)の資金調達を成功させており今最も熱いデータベースサービスなのです。
PlanetScaleの特徴
MySQL8を使ったサーバーレスDB
最新のMySQL8がPlanetScaleでは利用できるので、モダンな関数や仕様がサポートされています。
サーバーレスだから開発者側でサーバーを立てて管理する手間も無いのも楽。
ちなみにサーバーレスとはサーバーが無いということではなく、サーバーの管理やメンテナンスが開発者側で不要の意味なので間違えないようにしましょう。
ブランチ機能
ブランチ機能が実装されているのもPlanetScaleならではの強みで、例を上げると本番DBから枝を生やして開発用DBを作り出す事が可能になります。
これによって従来本番DBと開発DBで二つ管理しなければならなかった所を一つにできて、なおかつ大本の本番DBのスキーマ情報をそのまま利用できるから相互の整合性も担保しやすいのが嬉しいです。
そして開発DBのブランチで動作検証を済ませて、プルリクエスト的な感じでレビューの後改修を本番DBにマージさせることができます。
まさにGitの要領でDBを管理できるからとても便利。
外部キー制約がサポートされない
PlanetScaleでは外部キー制約がサポートされていないです。
外部キー制約とは親テーブルと子テーブルの二つのテーブル間でデータの整合性を保つために設定される制約のこと。
データベースの正規化する時に一つのテーブルを二つに分割して、子テーブルに親テーブルのidが紐付いたカラムを設定することがありますがそのカラムが外部キーって事になります。
PlanetScaleを使ってDBの設計をする時は外部キーを使わない様に工夫して設計する必要があるので注意です。
東京リージョン
PlanetScaleではデータベースのリージョンとして東京(tokyo)が用意されています。
(システム内部でAWSが使われているので、それに伴って東京も用意されているという事だと推測してます。)
国内にリージョンがあるという事はそれだけ近い位置で通信が可能なのでタイムラグが少なく快適に利用できるのが嬉しいですね。
自動バックアップ機能
無料プランでも自動バックアップ機能がついてきます。
もちろん手動でもできるし、バックアップスケジュールも変更可能。
デフォルトの設定だと1日一回自動でバックアップを取ってくれます。
登録
とりあえずまず最初に登録からやってみます。
サインイン画面からアカウントを作成します。
今回はGithubでサインインすることにします。
連携するとGitHubに紐付いたアドレスに確認メールが送られてくるので「Confirm email」を押せばアカウント登録は完了です。
DBを作る
その後はウェルカム画面的なやつが出てきて、「組織名」「DB名」「リージョン」を入れる箇所が出てくるので入力しましょう。
組織名は個人で使う分には何でもokで後から変更もできるので悩みすぎなくてok。
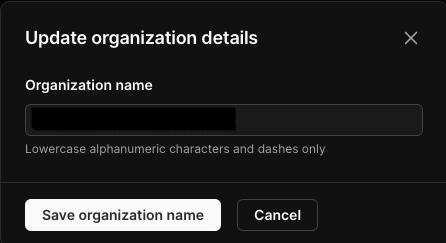
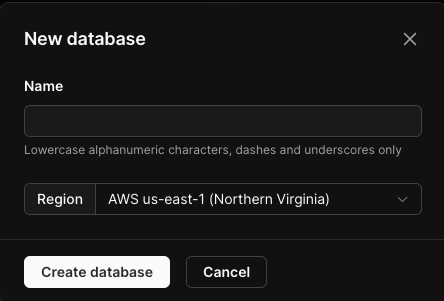
データベース名とリージョンは一度決めると変更出来ないっぽいので慎重に決めましょう。
リージョンに関しては東京(Tokyo)がおすすめ。
入力が終わると↓の様なダッシュボードが表示される。ここから色々な機能にアクセスできます。
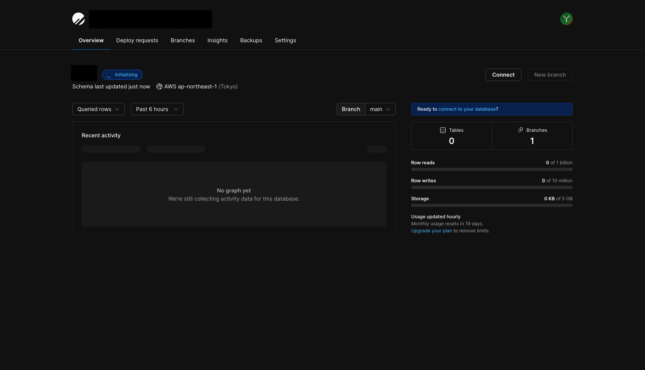
ここまででデータベースの作成がおわり。
ちなみに無料プランだと一つしかDBが作れない点に注意。
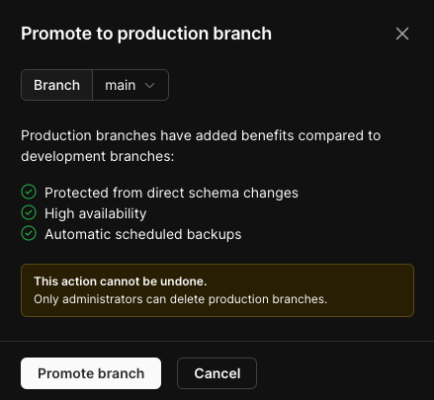
本番用ブランチを保護
DBを作るとmainブランチが既に作成されているのでこれを本番用DBとして誤って消したり更新したりできないように保護してみましょう。
Overview画面から「Promote a branch to production」をクリック。
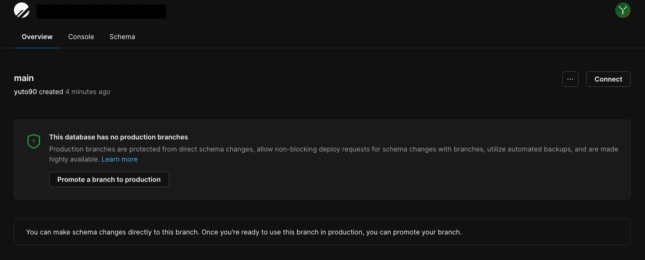
モーダルがでたらmainブランチが選択されているのを確認して「Promote branch」をクリックすればブランチの保護が完了です。
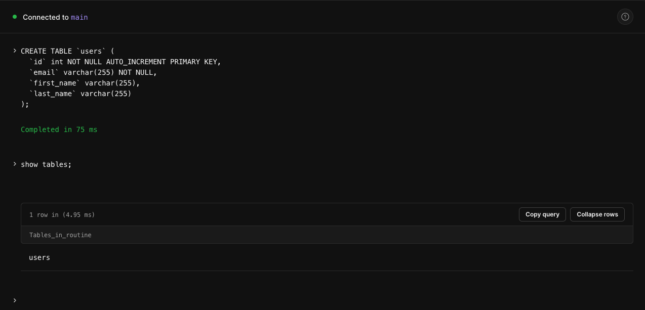
テーブルを作成してみる
まだDBしか作成していないので実際にテーブルを作ってみます。
テーブルを作るにはダッシュボードから「Console」を選択してSQLでCREATE文を流すだけでok。
今回は↓の感じのCREATE文を流してみる。
CREATE TABLE `users` (
`id` int NOT NULL AUTO_INCREMENT,
`email` varchar(255) NOT NULL,
`first_name` varchar(255),
`last_name` varchar(255),
PRIMARY KEY (`id`)
) ENGINE InnoDB,
CHARSET utf8mb4,
COLLATE utf8mb4_0900_ai_ci;流したらshow tables;でusersのテーブルが表示されれば無事テーブルが作成できています。
データをインサートしてみる
テーブルを作ったので実際にデータをインサートしてみましょう。
テーブル作った時と同じ様に「Console」から↓の感じのINSERT文を流してみます。
INSERT INTO `users` (id, email, first_name, last_name) VALUES (1, 'hitori@gmail.com', '後藤', 'ひとり');
...
select * from users;
+----+------------------+------------+-----------+
| id | email | first_name | last_name |
+----+------------------+------------+-----------+
| 1 | hitori@gmail.com | 後藤 | ひとり |
+----+------------------+------------+-----------+無事データがインサートできているのが確認できました。
ブランチ作成
次は試しにmainブランチから枝を生やして開発用のdevelopブランチを作成してみます。
ダッシュボードから「Branches」を選択して「New branch」をクリック。
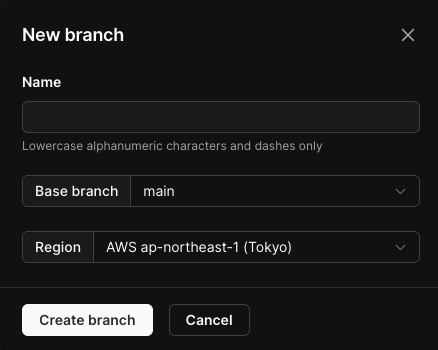
するとモーダルが出て「ブランチ名」「ベースとなるブランチ」「リージョン」を入力する。
入力できたら「Create branch」をクリック。今回は例として「develop」というブランチ名を入力しました。
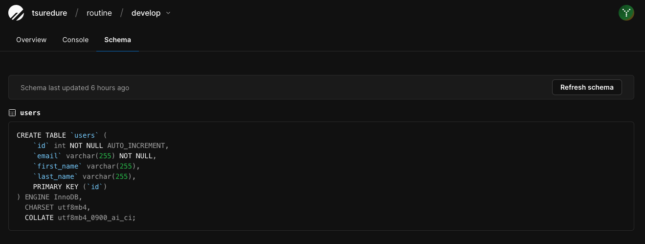
これでmainブランチと同じスキーマ情報を使用したdevelopブランチを作成できました。
実際に「Schema」をクリックするとmainブランチで決めたスキーマ(テーブル)情報がそのまま適用されているのが分かると思います。
PlanetScale CLIのインストール
PlanetScaleはGUIでも操作可能ですが、CLI経由でターミナル上からも同じ様に操作が可能です。
慣れればCLIの方が快適に操作できると思われるのでついでにインストールするのがおすすめです。
インストールはMacだったらbrew installで可能。
WindowsはScoop(アプリ導入、アプリ管理ツール)経由でインストールします。(Windows版のHomebrewみたいな感じ?)
今回は僕の環境の都合上Macのインストールのみ記載していきます。
brew install planetscale/tap/pscale無事インストールできているか確認してみましょう。
$ pscale --version
pscale version 0.124.0 (build date: 2022-11-17T22:37:49Z commit: 03f3582)バージョンが表示されたら無事インストールできています。
CLIからPlanetScaleにアクセスするにはまずログインをする必要があるので下記コマンドでログインします。
$ pscale auth loginコマンドを叩くとブラウザが自動で開いてターミナルに表示された自動でパスワードが入力されると思います。
(こんな感じのUXの高さがPlanetScaleの魅力の一つだと思います。)
入力されたら「Confirm code」をクリックしてログイン完了です。
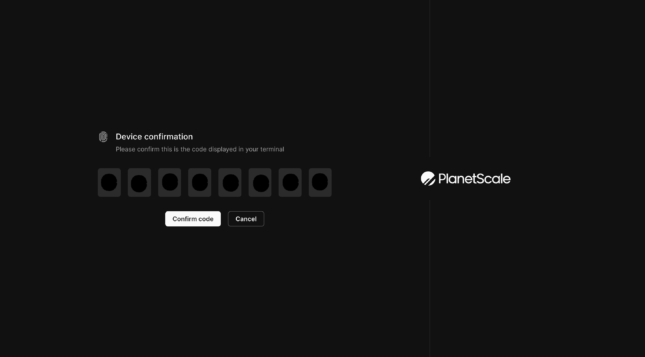
$ pscale auth login
Confirmation Code: XXXXXXXX
If something goes wrong, copy and paste this URL into your browser: https://auth.planetscale.com/oauth/device?user_code=XXXXXXXX
Successfully logged in.以上でCLIのインストールとログインは完了。
CLIで接続
CLIのインストールが出来たので実際にCLIからPlanetScale上のデータベースに接続してみましょう。
接続のコマンドはpscale shell {データベース名} {ブランチ名}の形式で叩けばokです。
今回はさっき作ったメインブランチに接続してみます。
$ pscale shell {データベース名} main
{データベース名}/|⚠ main ⚠|>保護してあるブランチはブランチ名の所に「⚠」のマークが付くので見分けやすいです。
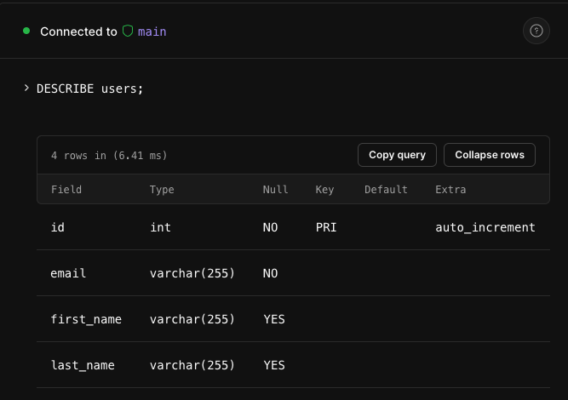
接続したらSELECT文でクエリを取得してみましょう。
{データベース名}/|⚠ main ⚠|> select * from users;
+----+------------------+------------+-----------+
| id | email | first_name | last_name |
+----+------------------+------------+-----------+
| 1 | hitori@gmail.com | 後藤 | ひとり |
+----+------------------+------------+-----------+さっきGUIからインサートしたデータが取得できました。
もちろんここでINSERT文を使ってデータをインサートする事もできます。
{データベース名}/|⚠ main ⚠|> INSERT INTO `users` (id, email, first_name, last_name) VALUES (2, 'ryou@gmail.com', '山田', 'リョウ');
{データベース名}/|⚠ main ⚠|> select * from users;
+----+------------------+------------+-----------+
| id | email | first_name | last_name |
+----+------------------+------------+-----------+
| 1 | hitori@gmail.com | 後藤 | ひとり |
| 2 | ryou@gmail.com | 山田 | リョウ |
+----+------------------+------------+-----------+Deploy request
さっきブランチを作りましたが、ブランチ機能があるということでPlanetScaleにはGitHubのPull requestの様な機能も用意されています。
その名も「Deploy request」と言って、例えばmainブランチからの派生でdevelopブランチを作り、テーブル構造を変えてみた時それをmainブランチにマージすると言ったことができます。
とりあえず先程作ったdevelopブランチでALTER TABLE文を流してテーブル構造を変えてみましょう。
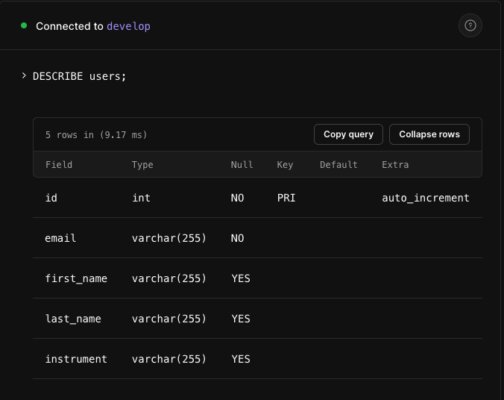
ALTER TABLE users ADD instrument VARCHAR(255);無事にテーブル構造をdevelopだけ変わっているのが分かると思います。
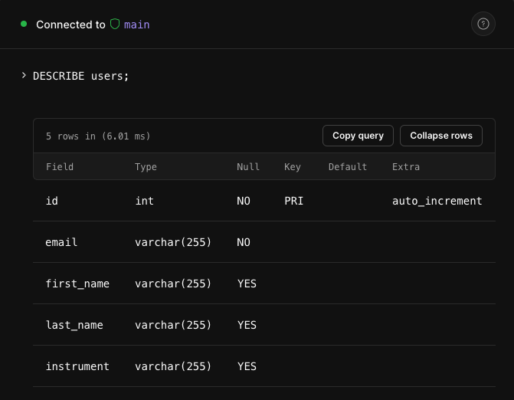
(instrumentカラムが追加された)
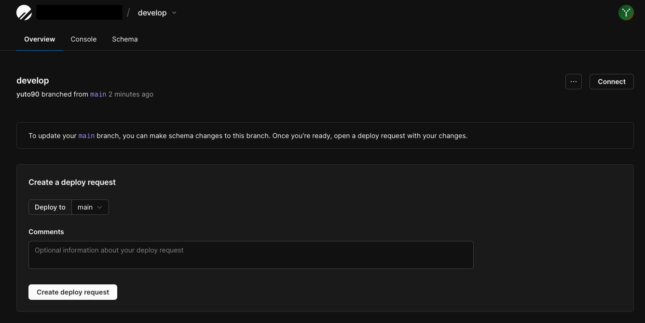
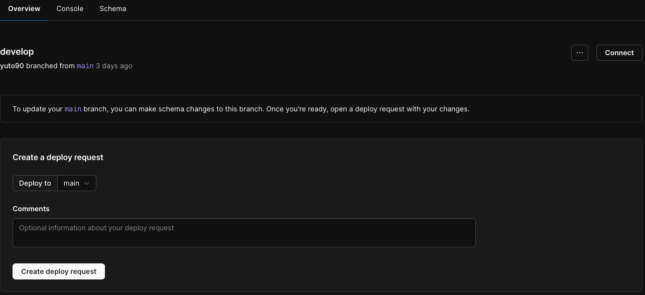
次にdevelopブランチのOverview画面で「Create a deploy request」を入力してDeploy requestを作成してみます。
入力内容はデプロイ先(マージ先)ブランチとコメントを入れるだけです。
できたら「Create deploy request」を押しましょう。
押したら↓の様な画面になって一番下の「Deploy changes」を押すとデプロイ(マージ)が実行されます。
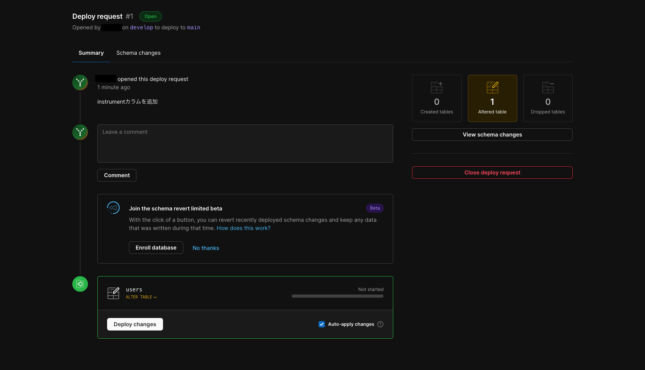
この時「View schema changes」を押すとGitの様に差分を確認可能です。
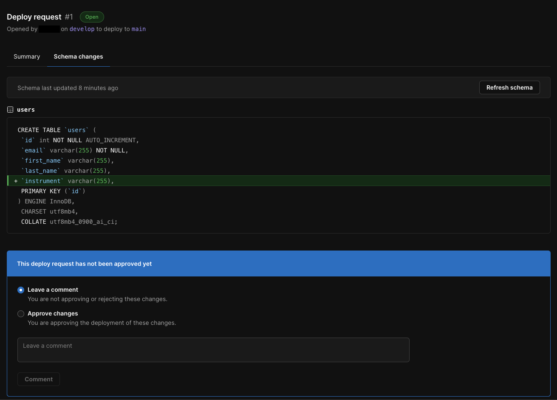
↓こんな感じで紫になったらデプロイ完了です。
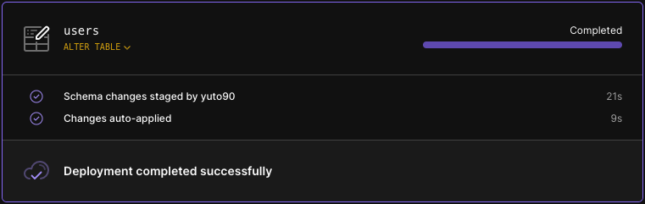
デプロイされると無事にmainブランチにカラムが追加されているのが確認できました。
おわり
今回は話題のサーバレスRDB、PlanetScale触ってみました。
とりあえず感想としては、GUIが洗練されていてブランチ機能や自動バックアップ機能とか無料で使える機能が多くて凄いと思いました。
今までFirestore使ってきたのですが、元々RDBの方が好きだったから実用できれば今後のメインにしたいですね。(無料枠だとデータベース1つしか作れない所は注意)
 PythonプログラムとFirestoreを接続して気軽にデータベースを利用する方法を解説!
PythonプログラムとFirestoreを接続して気軽にデータベースを利用する方法を解説!

